ARPANET 協議是如何工作的
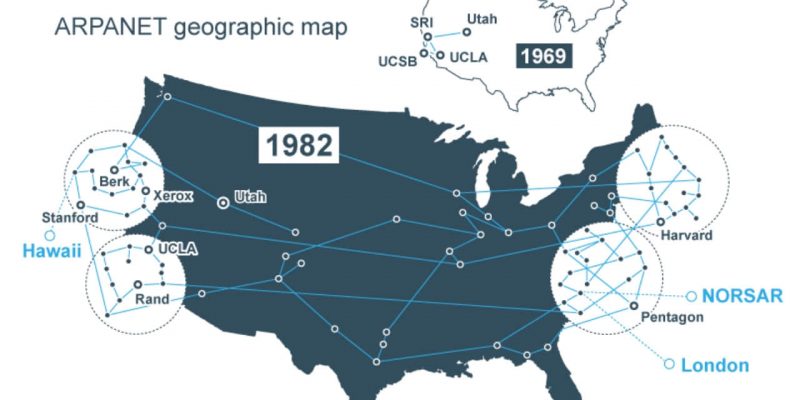
ARPANET 通過證明可以使用標準化協議連接完全不同的製造商的計算機,永遠改變了計算。在我的 關於 ARPANET 的歷史意義的文章 中,我提到了其中的一些協議,但沒有詳細描述它們。所以我想仔細看看它們。也想看看那些早期協議的設計有多少保留到了我們今天使用的協議中。
ARPANET 協議像我們現代的互聯網協議,是通過分層形式來組織的。 [1] 較高層協議運行在較低層協議之上。如今的 TCP/IP 套件有 5 層(物理層、鏈路層、網路層、傳輸層以及應用層),但是這個 ARPANET 僅有 3 層,也可能是 4 層,這取決於你怎樣計算它們。
我將會解釋每一層是如何工作的,但首先,你需要知道是誰在 ARPANET 中構建了些什麼,你需要知道這一點才能理解為什麼這些層是這樣劃分的。
一些簡短的歷史背景
ARPANET 由美國聯邦政府資助,確切的說是位於美國國防部的 高級研究計劃局 (因此被命名為 「ARPANET」 )。美國政府並沒有直接建設這個網路;而是,把這項工作外包給了位於波士頓的一家名為 「Bolt, Beranek, and Newman」 的諮詢公司,通常更多時候被稱為 BBN。
而 BBN 則承擔了實現這個網路的大部分任務,但不是全部。BBN 所做的是設計和維護一種稱為 介面消息處理機 (簡稱為 IMP) 的機器。這個 IMP 是一種定製的 霍尼韋爾 小型機 ,它們被分配給那些想要接入這個 ARPANET 的遍及全國各地的各個站點。它們充當通往 ARPANET 的網關,為每個站點提供多達四台主機的連接支持。它基本上是一台路由器。BBN 控制在 IMP 上運行的軟體,把數據包從一個 IMP 轉發到另一個 IMP ,但是該公司無法直接控制那些將要連接到 IMP 上並且成為 ARPANET 網路中實際主機的機器。
那些主機由網路中作為終端用戶的計算機科學家們所控制。這些計算機科學家在全國各地的主機站負責編寫軟體,使主機之間能夠相互通訊。而 IMP 賦予主機之間互相發送消息的能力,但是那並沒有多大用處,除非主機之間能商定一種用於消息的格式。為了解決這個問題,一群雜七雜八的人員組成了網路工作組,其中有大部分是來自各個站點的研究生們,該組力求規定主機計算機使用的協議。
因此,如果你設想通過 ARPANET 進行一次成功的網路互動,(例如發送一封電子郵件),使這些互動成功的一些工程由一組人負責(BBN),然而其他的一些工程則由另一組人負責(網路工作組和在每個站點的工程師們)。這種組織和後勤方面的偶然性或許對推動採用分層的方法來管理 ARPANET 網路中的協議起到很大的作用,這反過來又影響了 TCP/IP 的分層方式。
好的,回到協議上來
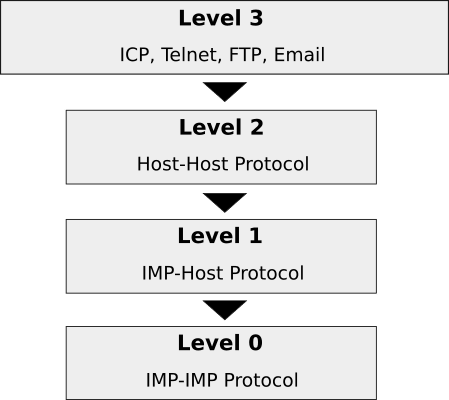
ARPANET 協議層次結構
這些協議層被組織成一個層次結構,在最底部是 「Level 0」。 [2] 這在某種意義上是不算數的,因為在 ARPANET 中這層完全由 BBN 控制,所以不需要標準協議。Level 0 的作用是管理數據在 IMP 之間如何傳輸。在 BBN 內部,有管理 IMP 如何做到這一點的規則;在 BBN 之外,IMP 子網是一個黑匣子,它只會傳送你提供的任意數據。因此,Level 0 是一個沒有真正協議的層,就公開已知和商定的規則集而言,它的存在可以被運行在 ARPANET 的主機上的軟體忽略。粗略地說,它處理相當於當今使用的 TCP/IP 套件的物理層、鏈路層和網路層下的所有內容,甚至還包括相當多的傳輸層,這是我將在這篇文章的末尾回來討論的內容。
「Level 1」 層在 ARPANET 的主機和它們所連接的 IMP 之間建立了介面。如果你願意,可以認為它是為 BBN 構建的 「Level 0」 層的黑匣子使用的一個應用程序介面(API)。當時它也被稱為 IMP-Host 協議。必須編寫該協議並公布出來,因為在首次建立 ARPANET 網路時,每個主機站點都必須編寫自己的軟體來與 IMP 連接。除非 BBN 給他們一些指導,否則他們不會知道如何做到這一點。
BBN 在一份名為 BBN Report 1822 的冗長文件中規定了 IMP-Host 協議。隨著 ARPANET 的發展,該文件多次被修訂;我將在這裡大致描述 IMP-Host 協議最初設計時的工作方式。根據 BBN 的規則,主機可以將長度不超過 8095 位的消息傳遞給它們的 IMP,並且每條消息都有一個包含目標主機號和鏈路識別號的頭部欄位。 [3] IMP 將檢查指定的主機號,然後盡職盡責地將消息轉發到網路中。當從遠端主機接收到消息時,接收的 IMP 在將消息傳遞給本地主機之前會把目標主機號替換為源主機號。實際上在 IMP 之間傳遞的內容並不是消息 —— IMP 將消息分解成更小的數據包以便通過網路傳輸 —— 但該細節對主機來說是不可見的。
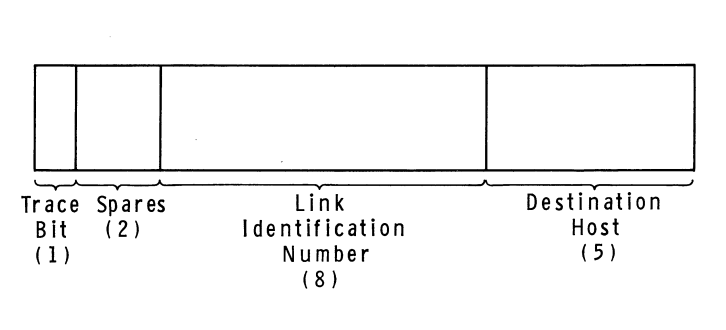
Host-IMP 消息頭部格式,截至 1969。 圖表來自 BBN Report 1763
鏈路號的取值範圍為 0 到 255 ,它有兩個作用。一是更高級別的協議可以利用它在網路上的任何兩台主機之間建立多個通信信道,因為可以想像得到,在任何時刻都有可能存在多個本地用戶與同一個目標主機進行通信的場景(換句話說,鏈路號允許在主機之間進行多路通信)。二是它也被用在 「Level 1」 層去控制主機之間發送的大量流量,以防止高性能計算機壓制低性能計算機的情況出現。按照最初的設計,這個 IMP-Host 協議限制每台主機在某一時刻通過某條鏈路僅發送一條消息。一旦某台主機沿著某條鏈路發送了一條消息給遠端主機後,在它沿著該鏈路發送下一條消息之前,必須等待接收一條來自遠端的 IMP 的特別類型的消息,叫做 RFNM( 請求下一條消息 )。後來為了提高性能,對該系統進行了修訂,允許一台主機在給定的時刻傳送多達 8 條消息給另一台主機。 [4]
「Level 2」 層才是事情真正開始變得有趣的地方,因為這一層和在它上面的那一層由 BBN 和國防部全部留給學者們和網路工作組自己去研發。「Level 2」 層包括了 Host-Host 協議,這個協議最初在 RFC9 中草擬,並且在 RFC54 中首次正式規定。在 ARPANET 協議手冊 中有更易讀的 Host-Host 協議的解釋。
「Host-Host 協議」 管理主機之間如何創建和管理連接。「連接」是某個主機上的寫套接字和另一個主機上的讀套接字之間的一個單向的數據管道。「 套接字 」 的概念是在 「Level-1」 層的有限的鏈路設施(記住,鏈路號只能是那 256 個值中的一個)之上被引入的,是為了給程序提供定址運行在遠端主機上的特定進程的一種方式。「讀套接字」 是用偶數表示的,而「寫套接字」是用奇數表示的;套接字是 「讀」 還是 「寫」 被稱為套接字的 「性別」。並沒有類似於 TCP 協議那樣的 「埠號」 機制,連接的打開、維持以及關閉操作是通過主機之間使用 「鏈路 0」 發送指定格式的 Host-Host 控制消息來實現的,這也是 「鏈路 0」 被保留的目的。一旦在 「鏈路 0」 上交換控制消息來建立起一個連接後,就可以使用接收端挑選的另一個鏈路號來發送進一步的數據消息。
Host-Host 控制消息一般通過 3 個字母的助記符來表示。當兩個主機交換一條 STR( 發送端到接收端 )消息和一條配對的 RTS( 接收端到發送端 )消息後,就建立起了一條連接 —— 這些控制消息都被稱為請求鏈接消息。鏈接能夠被 CLS( 關閉 )控制消息關閉。還有更多的控制信息能夠改變從發送端到接收端發送消息的速率。從而再次需要確保較快的主機不會壓制較慢的主機。在 「Level 1」 層上的協議提供了流量控制的功能,但對 「Level 2」 層來說顯然是不夠的;我懷疑這是因為從遠端 IMP 接收到的 RFNM 只能保證遠端 IMP 已經傳送該消息到目標主機,而不能保證目標主機已經全部處理了該消息。還有 INR( 接收端中斷 )、INS( 發送端中斷 )控制消息,主要供更高級別的協議使用。
更高級別的協議都位於 「Level 3」,這層是 ARPANET 的應用層。Telnet 協議,它提供到另一台主機的一個虛擬電傳鏈接,其可能是這些協議中最重要的。但在這層中也有許多其他協議,例如用於傳輸文件的 FTP 協議和各種用於發送 Email 的協議實驗。
在這一層中有一個不同於其他的協議: 初始鏈接協議 (ICP)。ICP 被認為是一個 「Level-3」 層協議,但實際上它是一種 「Level-2.5」 層協議,因為其他 「Level-3」 層協議都依賴它。之所以需要 ICP,是因為 「Level 2」 層的 Host-Host 協議提供的鏈接只是單向的,但大多數的應用需要一個雙向(例如:全雙工)的連接來做任何有趣的事情。要使得運行在某個主機上的客戶端能夠連接到另一個主機上的長期運行的服務進程,ICP 定義了兩個步驟。第一步是建立一個從服務端到客戶端的單向連接,通過使用服務端進程的眾所周知的套接字型大小來實現。第二步服務端通過建立的這個連接發送一個新的套接字套接字型大小給客戶端。到那時,那個存在的連接就會被丟棄,然後會打開另外兩個新的連接,它們是基於傳輸的套接字型大小建立的「讀」連接和基於傳輸的套接字型大小加 1 的「寫」連接。這個小插曲是大多數事務的一個前提——比如它是建立 Telnet 鏈接的第一步。
以上是我們逐層攀登了 ARPANET 協議層次結構。你們可能一直期待我在某個時候提一下 「 網路控制協議 」(NCP) 。在我坐下來為這篇文章和上一篇文章做研究之前,我肯定認為 ARPANET 運行在一個叫 「NCP」 的協議之上。這個縮寫有時用來指代整個 ARPANET 協議,這可能就是我為什麼有這個想法的原因。舉個例子,RFC801 討論了將 ARPANET 從 「NCP」 過渡到 「TCP」 的方式,這使 NCP 聽起來像是一個相當於 TCP 的 ARPANET 協議。但是對於 ARPANET 來說,從來都沒有一個叫 「網路控制協議」 的東西(即使 大英百科全書是這樣認為的),我懷疑人們錯誤地將 「NCP」 解釋為 「 網路控制協議 」 ,而實際上它代表的是 「 網路控制程序 」 。網路控制程序是一個運行在各個主機上的內核級別的程序,主要負責處理網路通信,等同於現如今操作系統中的 TCP/IP 協議棧。用在 RFC 801 的 「NCP」 是一種轉喻,而不是協議。
與 TCP/IP 的比較
ARPANET 協議以後都會被 TCP/IP 協議替換(但 Telnet 和 FTP 協議除外,因為它們很容易就能在 TCP 上適配運行)。然而 ARPANET 協議都基於這麼一個假設:就是網路是由一個單一實體(BBN)來構建和管理的。而 TCP/IP 協議套件是為網間網設計的,這是一個網路的網路,在那裡一切都是不穩定的和不可靠的。這就導致了我們的現代協議套件和 ARPANET 協議有明顯的不同,比如我們現在怎樣區分網路層和傳輸層。在 ARPANET 中部分由 IMP 實現的類似傳輸層的功能現在完全由在網路邊界的主機負責。
我發現 ARPANET 協議最有趣的事情是,現在在 TCP 中的許多傳輸層的功能是如何在 ARPANET 上經歷了一個糟糕的青春期。我不是網路專家,因此我拿出大學時的網路課本(讓我們跟著 Kurose 和 Ross 學習一下),他們對傳輸層通常負責什麼給出了一個非常好的概述。總結一下他們的解釋,一個傳輸層協議必須至少做到以下幾點。這裡的 「 段 」 基本等同於 ARPANET 上的術語 「 消息 」:
- 提供進程之間的傳送服務,而不僅僅是主機之間的(傳輸層多路復用和多路分解)
- 在每個段的基礎上提供完整性檢查(即確保傳輸過程中沒有數據損壞)
像 TCP 那樣,傳輸層也能夠提供可靠的數據傳輸,這意味著:
- 「段」 是按順序被傳送的
- 不會丟失任何 「段」
- 「段」 的傳送速度不會太快以至於被接收端丟棄(流量控制)
似乎在 ARPANET 上關於如何進行多路復用和多路分解以便進程可以通信存在一些混淆 —— BBN 在 IMP-Host 層引入了鏈路號來做到這一點,但結果證明在 Host-Host 層上無論如何套接字型大小都是必要的。然後鏈路號只是用於 IMP-Host 級別的流量控制,但 BBN 似乎後來放棄了它,轉而支持在唯一的主機對之間進行流量控制,這意味著鏈路號一開始是一個超載的東西,後來基本上變成了虛設。TCP 現在使用埠號代替,分別對每一個 TCP 連接單獨進行流量控制。進程間的多路復用和多路分解完全在 TCP 內部進行,不會像 ARPANET 一樣泄露到較低層去。
同樣有趣的是,鑒於 Kurose 和 Ross 如何開發 TCP 背後的想法,ARPANET 一開始就採用了 Kurose 和 Ross 所說的一個嚴謹的 「 停止並等待 」 方法,來實現 IMP-Host 層上的可靠的數據傳輸。這個 「停止並等待」 方法發送一個 「段」 然後就拒絕再去發送更多 「段」 ,直到收到一個最近發送的 「段」 的確認為止。這是一種簡單的方法,但這意味著只有一個 「段」 在整個網路中運行,從而導致協議非常緩慢 —— 這就是為什麼 Kurose 和 Ross 將 「停止並等待」 僅僅作為在通往功能齊全的傳輸層協議的路上的墊腳石的原因。曾有一段時間 「停止並等待」 是 ARPANET 上的工作方式,因為在 IMP–Host 層,必須接收到 請求下一條消息 (RFNM)以響應每條發出的消息,然後才能發送任何進一步的消息。客觀的說 ,BBN 起初認為這對於提供主機之間的流量控制是必要的,因此減速是故意的。正如我已經提到的,為了更好的性能,RFNM 的要求後來放寬鬆了,而且 IMP 也開始向消息中添加序列號和保持對傳輸中的消息的 「窗口」 的跟蹤,這或多或少與如今 TCP 的實現如出一轍。 [5]
因此,ARPANET 表明,如果你能讓每個人都遵守一些基本規則,異構計算系統之間的通信是可能的。正如我先前所說的,這是 ARPANET 的最重要的遺產。但是,我希望對這些基線規則的仔細研究揭示了 ARPANET 協議對我們今天使用的協議有多大影響。在主機和 IMP 之間分擔傳輸層職責的方式上肯定有很多笨拙之處,有時候是冗餘的。現在回想起來真的很可笑,主機之間一開始只能通過給出的任意鏈路在某刻只發送一條消息。但是 ARPANET 實驗是一個獨特的機會,可以通過實際構建和操作網路來學習這些經驗,當到了是時候升級到我們今天所知的互聯網時,似乎這些經驗變得很有用。
如果你喜歡這篇貼子,更喜歡每四周發布一次的方式!那麼在 Twitter 上關注 @TwoBitHistory 或者訂閱 RSS 提要,以確保你知道新帖子的發布時間。
- 協議分層是網路工作組發明的。這個論點是在 RFC 871 中提出的。分層也是 BBN 如何在主機和 IMP 之間劃分職責的自然延伸,因此 BBN 也值得稱讚。 ↩︎
- 「level」 是被網路工作組使用的術語。 詳見 RFC 100 ↩︎
- 在 IMP-Host 協議的後續版本中,擴展了頭部欄位,並且將鏈路號升級為消息 ID。但是 Host-Host 協議僅僅繼續使用消息 ID 欄位的高位 8 位,並將其視為鏈路號。請參閱 ARPANET 協議手冊 的 「Host-Host」 協議部分。 ↩︎
- John M. McQuillan 和 David C. Walden。 「ARPA 網路設計決策」,第 284頁,https://www.walden-family.com/public/whole-paper.pdf。 2021 年 3 月 8 日查看。 ↩︎
- 同上。 ↩︎
via: https://twobithistory.org/2021/03/08/arpanet-protocols.html
作者:Two-Bit History 選題:lujun9972 譯者:Lin-vy 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like





More in:Linux中國
捐贈 Let's Encrypt,共建安全的互聯網
Let's Encrypt 正式發布,已經保護 380 萬個域名
關於Linux防火牆iptables的面試問答
Lets Encrypt 已被所有主流瀏覽器所信任








